
TASM Notes 014
Fri Apr 05, 2024Pre-Meeting Chatting/News Update
Missed most of this today unfortunately. Although, as always, Zvi's Update is worth a read. Also, this paper is mentioned. Also, also, some long-time slack members have made it out to the actual meetup. Finally, none of us put much stock in the brand of AI apologia flavored "Don't worry; AI won't take away any jobs, it'll just create them".
AI Safety Via Debate
We're discussing this paper, presented by one of the authors.
The basic problem we have with LLMs is that they're not reliable. That is, even though they know lots of things, you can't rely on every response they give you. So they're really useful for
- people that already know at least kind of what they're doing
- domains where checking an answer is really easy
However, as models become more powerful, the amount of knowledge they have will exceed the amount of knowledge humans have. For instance, we might want them to go do some novel scientific research. At that point, we won't be able to check their answers easily. We're shortly going to get to the point where unless you're a human domain expert, you won't be able to validate any such response an LLM gives you.
A current solution RLHF; you depend on an existing infrastructure of human experts who can evaluate what the model emits and give yay/nay feedback on it. The problem is it really doesn't scale past human experts.
Idea! Let two models debate the answer. The relevant claim here is: it's easier for a human to judge the result of such a debate than it is for them to check the response from an LLM about a high-expertise-requiring domain. The original paper on this idea is AI Safety via Debate
Question from the audience: Given the strict debate format, wouldn't you basically need to be an expert judge to evaluate the result?
So, yes. You might need to have some expertise in order to judge the outcome of a debate, and you might need to know rather a lot about debating. BUT. There are some strategies to mitigate this, and also, if the goal is "get more frontier science done", it might be worth it anyway.
Previous work involved a lot of formal rules in debates (see that early paper link). The problem is that this lead to various cheese tactics that led to fairly reliable wins or draws by people on the "wrong side" of a debate.
Currently, this isn't actually more effective than RLHF. You wouldn't need to do this with GPT4, both because it's not good at debate, and because its responses aren't far enough beyond you for it to be worth it. You'd really want to use this for superhuman models, because RLHF doesn't scale that hard.
- PUB: How do you know that the judge chooses correctly?
- PUB: How do you design a debate such that it's always/mostly/usually harder to convince the judge of something incorrect than of something correct?
- PUB: How do you detect truth in a question space that is at the level of human frontier science? (This is exactly where the paradigm problem bites hardest)
- PUB: How do you guard against a model just not bringing up some pitfall to an argument? Or two models cooperating in a way that defeats the debate format?
A more recent update involves teaching Claude to debate. One current limitation is that we really only train models with "known answer" debates. That is, debates are about some question we know the answer to. This has some complications, because it's possible that the current regime is encouraging convincingness rather than honesty.
- Debate Use Case 1
- Extract trustworthy information from untrustworthy models
- Debate Use Case 2
- Make models more trustworthy
- If you have a debate protocol where the best strategy is to give honest responses, then we can use that as a training basis for honest models.
- To some extent, we already do this with RLHF, but this is limited to the domains where human judges have the insight to make correctness calls
Important questions
- Can a less capable judge accurately evaluate debates between more capable models?
- Does debate still work as model capabilities increase?
- Is there promise to debate as a long term scalable pursuit? (Currently, there's a lot of open questions for the general case)
Question from the audience: instead of focusing on a debate between a "true" fact and "false" fact, can we do a thing where a model is arguing for a position and the opponent is supposed to just poke holes in it?
- This rhymes with a related alignment strategy which is market making
Isn't collusion a pretty big problem?
Kind of. If your models are already situationally aware, you're pretty screwed.
Can you incentivize the models to be really thorough? Like, ensure that they don't hold back information that would be damaging to their case?
You can kind of incentivize this through the judges' scores, and the debate protocol itself rather than a deliberate, additional training effort.
LLM Experiments
- Testing superhuman models is tricky, because they kind of don't exist yet.
- Current preferred approach - information asymmetry. You train a system that's weaker than some humans and stronger than other humans on a particular domain. Then you have the weak humans judge the debate.
- Example setup: there's a story about some event that both debaters have access to, but that the judge doesn't have access to. This is called a "reading comprehension debate".
- Get some science fiction story from Project Gutenberg.
- LLMs are fed the story, the judge is not shown it. They LLMs are allowed to quote from the story, and refer to it.
- There are four different formats of "debate"
- Naive - there is no model, the judge just gets the question and answers it
- Consultancy - there is a model and the judge asks questions
- Debate - there are two models, the judge observes the debate and makes a decision
- Interactive debate - there are two models, and the judge is watching live, and is allowed to ask for clarifications
Extra notes on the quotes: the quotes were correlated to the story. So, if a model quoted the story directly, it would be highlighted in green, whereas if a model claimed that something is a quote but isn't it would be highlighted in yellow. The questions for this set were constranied such that you needed a fair bit of context from the story in order to answer it (to avoid questions that could be settled by a known originating-from-the-story quote). Also, we're discounting getting Eulered, so the judge is instructed to accept answers only when they've been decisively convinced. An "I guess I'll go along because I don't know enough to question it" translates to "not convinced".
Experimental results
There's some fairly involved graphs here. Bar chart sets that show accurate results of Naive, Consultancy, Debate and Interactive Debate, along with an "Expert" bar ("Expert" is the name for the situation where the judge is shown the question and the full story). The groups each represent different judges, all of which are judging two GPT4 debaters. The judges are Llama2, GPT4, GPT3.5, GPT4Turbo, Claude and Human. It was an expanded version of this:
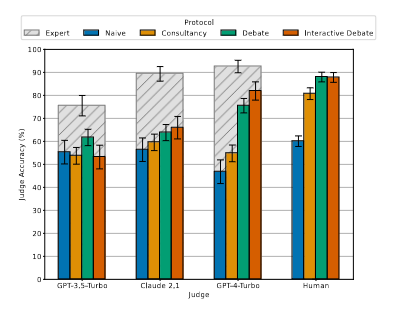
The interesting results are
- Llama2 sucks at this
- Claude Opus judges narrowly beat out the human judges
- Debate consistently beats Consultancy which consistently beats Naive. Expert obviously consistently beats the rest
- Interactive debate does not consistently beat Debate. It also doesn't do significantly worse; it looks like it's pretty neck-and-neck between the approaches.
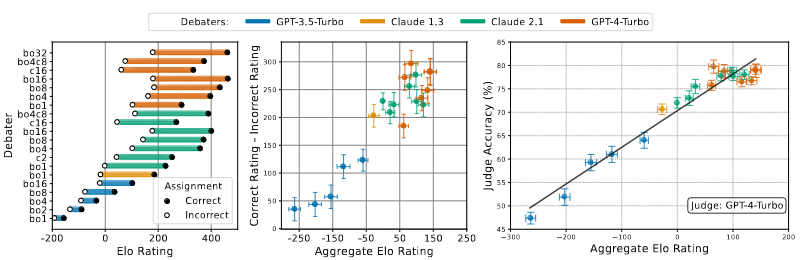
More graphs! Just highlights this time
- It looks like the harder you train these, the more differential is between the accurate and inaccurate models
- This implies that increasing effectiveness of the debaters makes it easier to argue for the accurate response relative to the inaccurate response
Important next research project: do a bunch of this stuff with helpful-only models. (The question to resolve here: Are their deceptive abilities nerfed by harmlessness training or does this approach genuinely make accuracy easier to argue with).
More important next research project: do a bunch of this stuff but on larger, real-world applicable debates. One interesting question here is "Once you have the full internet to quote from, does the property of it getting relatively harder to argue for the inaccurate side of the debate hold?"
Key Result From The Experiment - As the debaters get more skilled, their self-play debates end up more frequently convincing the judge of hte accurate answer. Also, anything below the level of GPT4 can't be an accurate judge, basically at all.
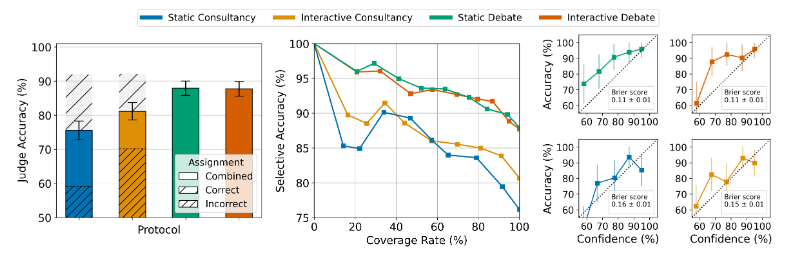
Even more graphs! Still only highlights
- Humans are sometimes, about 20% of the time, fooled by competent consultancy models into coming to the incorrect conclusion
- Humans are unlikely to be confidently wrong with debates, but not with consultancy
- Ensembles are situations where you have multiple judges judging the same debate. This tends to increase accuracy significantly from 1 to 8 judges (they tend to converge on the correct answer)
- This is not just showing a bunch of different judges the same debate, which you could presumably also do, but rather rolling
nseparate debates on the same parameters for each ofnjudges.
- This is not just showing a bunch of different judges the same debate, which you could presumably also do, but rather rolling
Conclusions
The results so far are encouraging but preliminary. There's more ongoing research at Anthropic, GDM and OpenAI. We may be able to implement a full debate protocol "soon". Expected to be more useful in early-AGI regime, unclear if it'll work for superintelligences.
Anthropic is intending to publish more in this space, but it doesn't seem like this is something that is strategically being kept quiet in the interest of keeping capabilities advancements down, they just haven't gotten around to publishing yet.
The threat model where a debater is trained and gets into production with the intention of throwing a debate at a critical moment is still plausible, and an open question for further research.
The Pub
And then we went off to a well-earned pub evening where we took up a bunch of the open questions from above with gusto. If that sounds interesting, join us next time.
