
Dissecting Squares
Mon Apr 29, 2013I know I posted earlier, but this has to come out of my head. And I don't think I'll have time to do much more writing this week, despite the fact that there are at least three other things on my mind that I need to idea peel.
So...
That's what I'm thinking.
And here's an attempt at forcing this primitive tool called "English" to explain what it means in my head.
First off, this is what I was thinking previously. Which is to say, not much in particular; just working my way up to meaningfully tearing into the problem. The basic problem is that there are lots of ways to dissect a square into smaller, integer-sized squares, and brute-forcing it isn't going to be viable for very high ns. In fact, from what I've observed, it took multiple days of compute time to solve for 16, and that's not encouraging.
Thing is, there are lots of little ways to cut out a lot of the brute-force work required for the calculation. An approach that starts from the universe of possibilities and filters isn't going to get very far, but we can constrain that universe pretty significantly if we pick our model carefully, and I think I have.
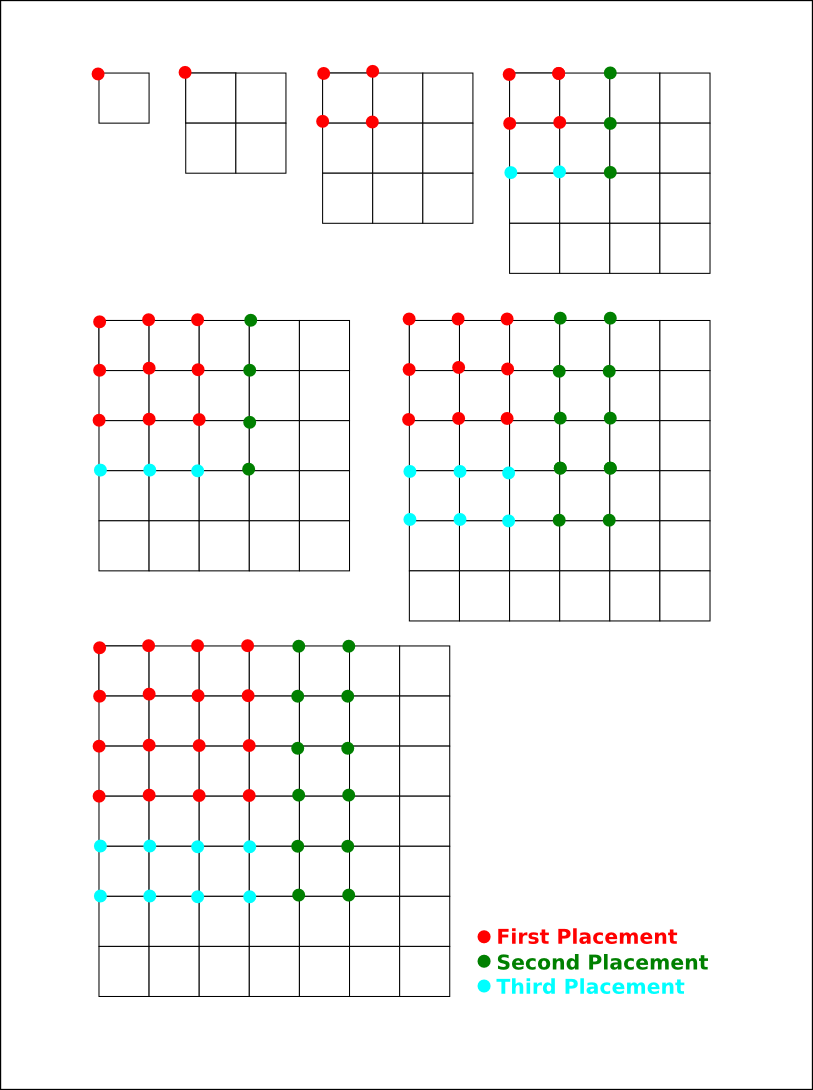
Characteristics of the Optimal Dissection Model
Cut at the base
A huge contribution to the final tally of work is going to be figuring out where 1x1 squares can fit. If you look at each of them as a Placement, you'll be overwhelmed pretty quickly. An easy way out of that is picking a model that lets you ignore 1x1 squares, and the easiest obvious way to do that is using a sparse array with the understanding that any unrecorded placements actually represent 1x1 squares. This lets you ignore a bunch of StartingPoints too (more on that in a moment).
Take symmetry into account
A second huge contribution to the bottom line of work for this problem is that you need to recompute a lot of dissections which you must then de-duplicate later. I don't think we can lick this one entirely; we'll still need to do Set insertions at some point in the process just to make sure we're not counting anything twice. But. We can cut out a lot of them. Specifically, since the problem already mentions rotations and reflections, we don't need to Place any squares that we know will be picked up by some other permutations' reflections or rotations. That can greatly reduce the number potential starting nodes these placement trees. It also means we'll want a representation where rotate and reflect are really, really fast operations. The sparse array approach seems to be better than using an explicit grid, but I'm not quite convinced it's optimal.
Bring it all together
So what we've got as a 10000-foot-view for the process is this:
- find all
StartingPoints unfoldeach starting point, starting with squares of sizenxnand working your way down to2x2recordthe null dissection (a grid full of 1x1 squares)- return the size of the set of recorded dissections
- A
StartingPointis any point on our grid from'(0 0)to ``(,(limit n) ,(limit n))`. - The
limitofnis(- (ceiling (/ n 2)) 1) - To
unfoldaStartingPoint,insertthe solitary placement as a dissection (remember, any empty spaces are treated as "placed 1x1 squares"), then find allfreeSecondPoints andunfoldthem. - A
SecondPointis anyfreeStartingPoint, or any point between(,(limit n) ,y)` and(,(- n 2) ,y). Again, any others should be represented amongreflections/rotate`ions of other dissections. - To
unfoldaSecondPoint,insertit as a dissection, thenunfoldall remainingfreepoints on the grid (there's probably a way to cut this step down, but I can't see it yet). - To
unfoldany other point,insertit as a dissection, andunfoldall remainingfreepoints until there's no more room. - To
inserta dissection, performSetinsertion on each of itsrotateions andreflections into the set of all insertions for this particular grid. - A
freepoint is one where there's enough room to put a square larger than 1x1 (this implies thatplacecould probably remove some additional squares from the potential starting pool to make calculating this easier).
Granted, that's easier said than done. I get the feeling that when I actually go to implement this fully, a whole bunch of problems are going to crop up, but at least I have a half-way decent starting point.
